
TL;DR
Dieser Beitrag beschreibt meine Suche nach einem Netzwerk-Fehler der am Ende doch an ganz anderer Stelle lag, als zuerst vermutet. Wer Dingen gern auf den Grund geht, sollte unbedingt weiterlesen.
Mittlerweile verdiene ich meine Brötchen schon ein halbes Jahr lang mit dem Troubleshooting kniffliger Netzwerkprobleme. Da ist es an der Zeit, endlich mal wieder einen Blog-Beitrag zu verfassen!
Ein Kunde meldet sporadische Probleme beim Aufruf verschiedenster Webseiten. Wenn der Fehler auftritt, gibt es einen Timeout im Browser. Anschließend klickt man auf Aktualisieren und die Seite wird sofort geladen. Ein festes Muster lässt sich nicht ausmachen. Also musste ein Packet Capture her, um der Sache auf den Grund zu gehen.
Als Testobjekt diente www.heise.de. Um in dem ganzen Getöse auf der Netzwerkschnittstelle den Überblick zu behalten, haben wir direkt mal einen Display Filter auf die zugehörige IP-Adresse gesetzt: ip.addr == 193.99.144.85

Das Verhalten ist durchaus seltsam: Zuerst kommt ein TCP Handshake. Nach 10 Sekunden schickt der Client ein TCP Keep-Alive, woraufhin der Webserver die Verbindung schließlich mit einem RESET abwürgt – zu Recht! Wie sollte es denn im Normalfall aussehen?
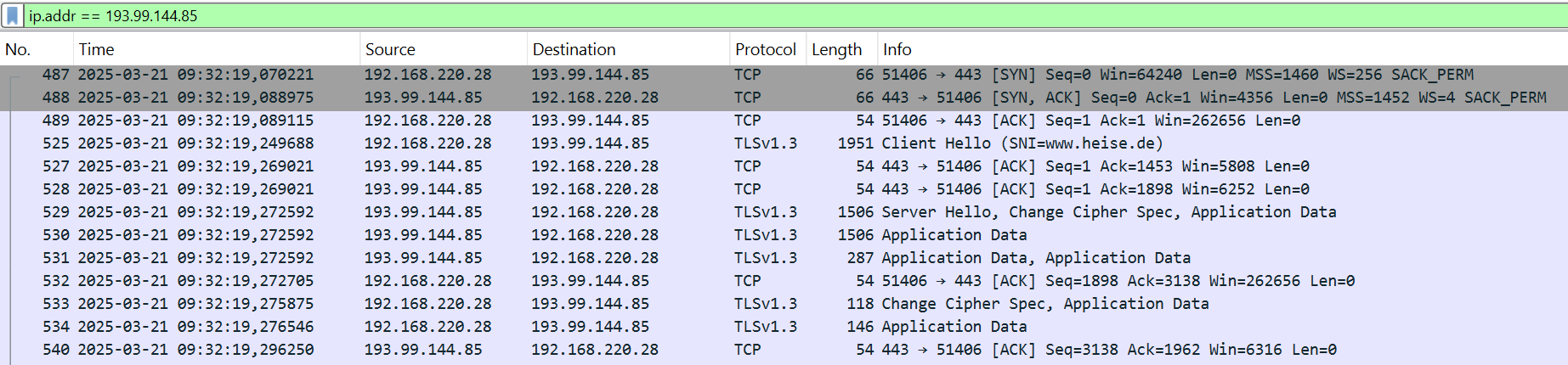
Wie Abbildung 2 zeigt, folgt nach Abschluss des TCP Handshakes normalerweise ein TLS Handshake, welcher durch ein Client Hello gestartet wird. Der Client ist hier also in der Pflicht. Super – ein Client-Problem! Dann bin ich als Netzwerker also raus. 😉
So funktioniert das bei uns nicht! Ein wesentlicher Bestandteil meiner aktuellen Anstellung ist die abteilungsübergreifende Entstörung, verbunden mit dem Ziel, Ticket-Ping-Pong zu minimieren und dadurch möglichst schnell eine Lösung für den Kunden zu finden. (Natürlich haben wir an dieser Stelle trotzdem auch den Client-Support ins Boot geholt.)
Dem aufmerksamen Leser ist es möglicherweise nicht entgangen, dass der Display Filter in Abbildung 1 zu einer kleinen Lücke in den Paketnummern geführt hat. Das ist eigentlich ganz normal und nicht weiter beachtenswert, für diese konkrete Situation aber der Schlüssel zur Lösung: Denn eines hatten alle fehlerhaften Paketmitschnitte gemeinsam: Zwischen TCP Handshake und Keep-Alive versucht der Client, eine HTTPS-Verbindung zu einer IP-Adresse 48.209.X.Y aufzubauen, was jedoch scheitert (Abbildung 3).

Leider wird für diese Adressen kein Reverse DNS gepflegt. Laut RIPE Datenbank gehören sie aber zu Microsoft. Weitere Recherchen ergaben dann schließlich, dass unter diesen Adressen Dienste für Microsoft Defender SmartScreen laufen. Ein Blick in unsere Firewall-Logs zeigte Hunderte von Timeouts und das nicht nur für diesen Kunden, sondern auch für einige andere. Die Endpoint Protection klinkt sich also bei jedem Webseiten-Aufruf ein, vermutlich um die angesprochene URL vor Aufbau der TLS-Verbindung auf Bösartigkeit zu prüfen. Der dabei auftretende Timeout ist das eigentliche Problem, das es zu lösen galt.1 Nach dem Timeout versuchte der Client übrigens einfach eine andere Adresse aus 48.209.X.Y, die dann meistens funktionierte – lediglich eine Handvoll der Adressen machte Ärger.
Mit Traceroute konnte ich feststellen, dass die Pakete bis zu einem Microsoft-Router in Dublin gelangen und dass ab dort keine Antwort mehr zurückkommt. Also ein Routing-Problem bei Microsoft!? Grund genug, dort einen Case zu öffnen. Der ging einige Zeit lang in die falsche Richtung, denn wie der Support (richtig) feststellte, gab es ein Problem beim Verbindungsaufbau zu SmartScreen. Das heißt aber noch lange nicht, dass das zugehörige Team unser Problem lösen kann. Denn was sollen die schon tun, wenn kein TCP Handshake zustande kommt?
Letztendlich gelangte ich dann doch zum Azure Networking Team. Dort konnte man mir sehr glaubhaft versichern, dass man eine Menge TCP SYNs erhält und auch entsprechend SYN/ACKs über ein Peering an unseren Internet Service Provider sendet, welche dann aber unbeantwortet bleiben. Der ISP wollte das natürlich nicht wahr haben. Dort meinte man, dass „mit Microsoft sowieso immer alles komisch sei und der Fehler bestimmt dort liege.“ Nach vehementem Widerspruch meinerseits – insbesondere dadurch untermauert, dass die Zielsysteme bei Microsoft von meinem privaten Anschluss aus erreichbar waren – willigte man schließlich in ein gemeinsames Troubleshooting mit Microsoft ein.
Zum Termin stellten beide Seiten fest, dass es keine Anzeichen für Probleme im Routing gibt und trotzdem kam der Traffic bei uns nicht an. Andere Microsoft-Systeme waren über das gleiche Peering aber sehr wohl für uns erreichbar. An unseren Routen, die der ISP zu Microsoft annonciert, konnte es also auch nicht liegen. Offenbar war das Phänomen abhängig von der Absender-IP bei Microsoft.
Um das Problem nun abschließend zu lösen, muss man wissen dass unser ISP auch DDoS-Protection für uns macht und dabei kommt es im Gegensatz zum normalen Routing auch tatsächlich auf die Absender-IP an. Als der ISP dann testweise begann, den problematischen Traffic am DDoS-Cluster vorbei zu routen, erhielt ich spontan Antworten auf meine Pings. 🎉
Natürlich hatte ich diesen Verdacht schon viel länger und hatte dies bereits mehrfach zur Debatte gestellt, aber der ISP war sich seiner Sache eben sehr sicher… Außedem wollte ich die Spannung hoch halten. 😉
Und was lernen wir nun daraus? Nichts ist, wie es scheint! Aus vermeintlich ungeduldigen Nutzern, denen jeder Klick zu lange dauert und die in der hintersten Ecke des Büros sitzen, wo das WLAN kaum noch stark genug ist, können eben doch mal handfeste Störungen im ISP-Bereich werden.
P.s.: Wenn der Support von Microsoft und ISP zeitweise auch etwas frustrierend war, sind beide doch um Längen besser als der Sophos-Support.
Foto von Randy Jacob auf Unsplash
- Das Ergebnis der Überprüfung wird eine Zeit lang im Cache gehalten, weshalb für eine konkrete Webseite dann erstmal kein Timeout mehr auftritt. ↩︎